
来源:奇异摩尔 作者:奇异摩尔
近一段时间以来,DeepSeek现象级爆火引发产业对大规模数据中心建设的思考和争议。在训练端,DeepSeek以开源模型通过算法优化(如稀疏计算、动态架构)降低了训练成本,使得企业能够以低成本实现高性能AI大模型的训练;在推理端,DeepSeek加速了AI应用从训练向推理阶段的迁移。因此,有观点称,DeepSeek之后算力需求将放缓。不过,更多的国内外机构和研报认为,DeepSeek降低了AI应用的门槛,将加速AI大模型应用落地,吸引更多的企业进入这个赛道,算力需求仍将继续增长,不过需求重心从“单卡峰值性能”转向“集群能效优化”。比如,SemiAnalysis预测,全球数据中心容量将从2023年的49GW增长至2026年的96GW,其中新建智算中心容量将占增量的85%。近日,全球四大巨头(Meta、亚马逊、微软及)公布的2025 AI基础设施支出总计超3000亿美元,相比2024年增长30%。
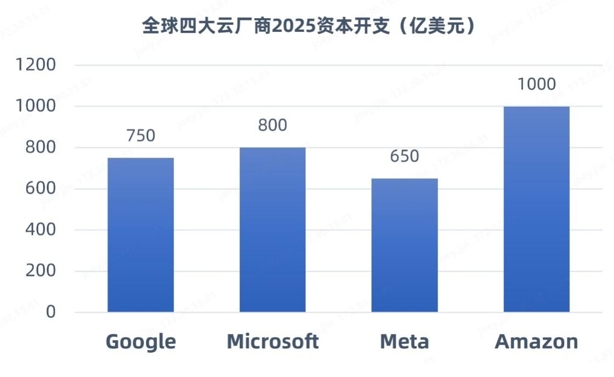
(数据来源:科技巨头公开披露报告)

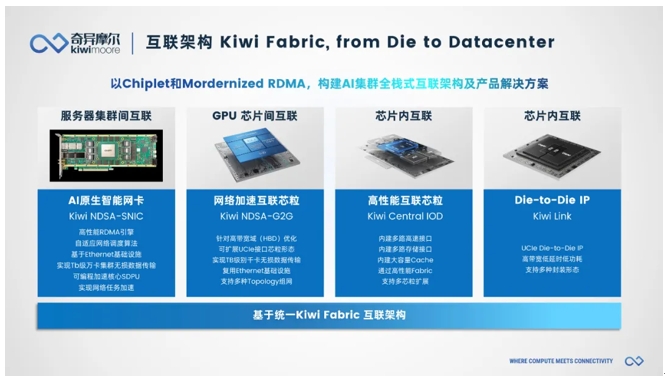
为此,作为行业领先的AI网络全栈式互联产品及解决方案提供商,奇异摩尔给出了一套极具竞争力的解决方案——基于高性能RDMA和Chiplet技术,利用“Scale Out”“Scale Up”“Scale Inside”三大理念,提升算力基础设施在网间、片间和片内的传输效率,为智能算力发展赋能。
Scale Out——打破系统传输瓶颈
DeepSeek的成功证明了开源模型相较于闭源模型具有一定的优越性,随着模型的智能化趋势演进,模型体量的增加仍然会是行业发展的主要趋势之一。为了完成千亿、万亿参数规模AI大模型的训练任务,通用的做法一般会采用Tensor并行(TP)、Pipeline并行(PP)、和Data并行(DP)策略来拆分训练任务。随着MoE(Mixture of Experts,混合专家)模型的出现,除了涉及上述并行策略外,还引入了专家并行(EP)。其中,EP和TP通信数据开销较大,主要通过Scale Up互联方式应对。DP和PP并行计算的通信开销相对较小,主要通过Scale Out互联方式应对。
因而,如下图所示,当下主流的万卡集群里存在两种互联域——GPU南向Scale Up互联域(Scale Up Domain,SUD)和GPU北向Scale Out互联域(Scale Out Domain,SOD)。田陌晨强调:“以Scale Up和Scale Out双擎驱动方式构建大规模、高效的智算集群,是应对算力需求爆发的有效手段。”
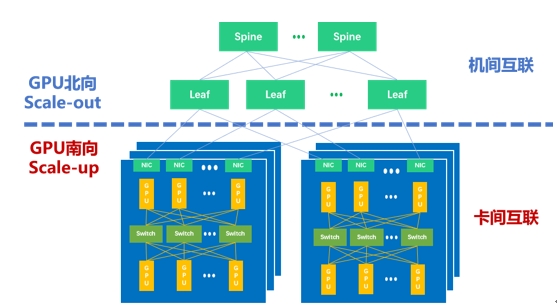
智算集群里的Scale Up和Scale Out
在这个集群网络中,Scale Out专注于横向/水平的扩展,强调通过增加更多计算节点实现集群规模的扩展。当前,远程直接内存访问(RDMA)已经成为构建Scale Out网络的主流选择。作为一种host-offload/host-bypass技术,RDMA提供了从一台计算机内存到另一台计算机内存的直接访问,具有低延迟、高带宽的特性,在大规模集群中扮演着重要的角色。如下图所示,RDMA主要包含InfiniBand(IB)、基于以太网的RoCE和基于TCP/IP的iWARP。其中,IB和以太网RDMA是算力集群里应用最广泛的技术。
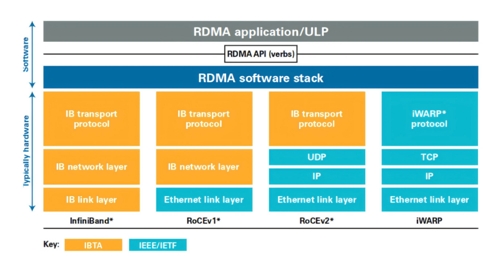
随着集群规模增大,以太网RDMA获得了主流厂商的广泛支持。以太网RDMA同样具有高速率、高带宽、CPU负载低等优势,在低时延和无损网络特性方面也已经和IB性能持平。同时,以太网RDMA具有更好的开放性、兼容性和统一性,更利于做大规模的组网集群。从一些行业代表性案例来看,如字节跳动的万卡集群,Meta公司的数万卡集群,以及特斯拉希望打造的十万卡集群,都一致选择了以太网方案。此外,因为硬件通用和运维简单,以太网RDMA方案更具性价比。
虽然以太网RDMA已经被公认是未来Scale Out的大趋势,不过田陌晨指出:“如果是基于RoCEv2构建方案仍存在一些问题,比如乱序需要重传,负载分担不完美,存在Go-back-N问题,以及DCQCN 部署调优复杂等。在万卡和十万卡集群中,业界需要增强型以太网RDMA以应对上述这些挑战,超以太网传输(Ultra Ethernet Transport,UET)便是下一代AI计算和HPC里的关键技术。”
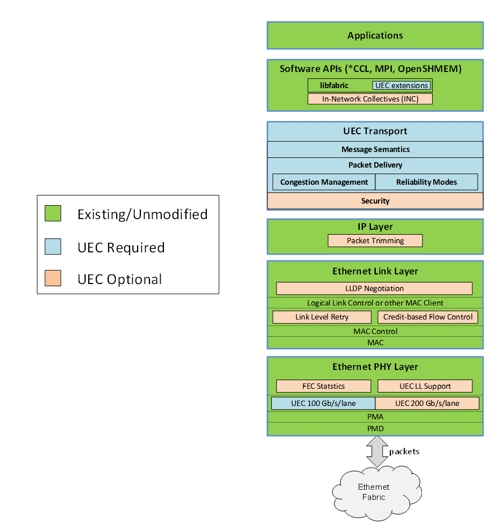
为了能够进一步发挥以太网和RDMA技术的潜能,博通、思科、Arista、微软、Meta等公司牵头成立了超以太网联盟(UEC)。如下图所示,在UEC规范1.0的预览版本中,UEC从软件API、运输层、链路层、网络安全和拥塞控制等方面对Transport Layer传输层做了全面的优化,关键功能包括FEC(前向纠错)统计、链路层重传(LLR)、多路径报文喷发、新一代拥塞控制、灵活排序、端到端遥测、交换机卸载等。根据AMD方面的数据,UEC就绪(UEC-ready)系统能够提供比传统RoCEv2系统高出5-6倍的性能。
奇异摩尔打造的Kiwi NDSA-SNIC AI原生智能网卡便是一款UEC就绪方案,性能比肩全球标杆ASIC产品。Kiwi NDSA SmartNIC提供领先行业的高性能,支持高达800Gbps的传输带宽,提供低至μs级的数据传输延时,满足当前数据中心行业400Gbps-800Gbps升级需求,可实现Tb级别万卡集群间无损数据传输。

此外,Kiwi NDSA-SNIC还拥有很多其他的关键特性。比如,Kiwi NDSA-SNIC具有出色的高并发特性,支持多达数百万个队列对,可扩展内存空间达到GB;Kiwi NDSA-SNIC具有可编程性,可应对各种网络任务加速,为Scale Out网络带来持续创新的功能,并保证与未来的行业标准无缝兼容。
综合而言,奇异摩尔的Kiwi NDSA-SNIC AI原生智能网卡是一个拥有高性能、可编程的Scale Out网络引擎,将开启AI网络 Scale Out发展的新篇章。田陌晨称:“当前,奇异摩尔已经成为UEC联盟成员。随着以太网逐渐过渡到超以太网,奇异摩尔愿携手联盟伙伴共同探讨并践行Scale Out相关标准的制定和完善,并第一时间为行业带来性能领先的UEC方案,推动AI网络 Scale Out技术向前发展。”

奇异摩尔UEC会员(来源:UEC官网)
Scale Up——让计算芯片配合更高效
和横向/水平扩展的Scale Out不同,Scale Up是垂直/向上扩展,目标是打造机内高带宽互联的超节点。上述提到,TP张量并行以及EP专家并行需要更高的带宽和更低的时延来进行全局同步。通过Scale Up的方式,将更多的算力芯片GPU集中到一个节点上,是非常有效的应对方式。如今的Scale Up实际上就是一个以超高带宽为核心的机内GPU-GPU组网方式,还有一个名称是超带宽域(HBD,High Bandwidth Domain)。
英伟达GB200 NVL72的推出引领着国内外AI网络生态对HBD技术的广泛探讨。英伟达GB200NVL72服务器是一个典型的超大HBD,实现了36组GB200(36个Grace CPU,72个B200 GPU)之间的超高带宽互联。在这个HBD系统里,第五代 NVLink是最关键的,它能够提供GPU-GPU之间双向1.8TB的传输速率,使得这个HBD系统可以作为一个大型GPU去使用,训练效率相较于H100系统提升了4倍,能效提升了25倍。
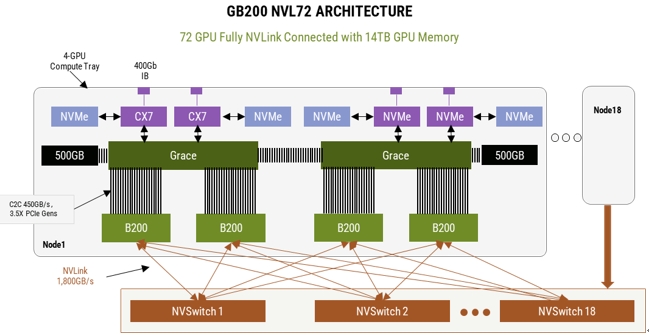
DeepSeek事件引发了业界对于上述NVLink和HBD需求的不同预期。但中长期发展来看,相比软件迭代速度以小时来计算,硬件的迭代则是以年为计算的循序渐进过程,不会一蹴而就。据SemiAnalysis预计大型模型的标准只会随着未来的模型发布而继续升高,但从经济效用上来说,其所对应的硬件必须坚持使用并有效 4-6 年,而不仅仅是直到下一个模型发布。
对此,田陌晨认为:“未来MoE模型的进阶路线在一定程度上存在不确定性,创新随时可能发生。但国产AI网络的生态闭环势在必行。英伟达NVLink和Cuda的护城河仍然存在,首先要解决Scale Up互联国产替代方案有没有的问题,再来看做到哪种程度。未来随着国产大模型、芯片架构等软硬件生态的协同发展,有望逐步实现国产算力闭环。”
如今,科技巨头正联合生态上下游在GPU-GPU高效互联方面主要分为两个流派:内存语义和消息语义。内存语义Load/Store/Atomic是GPU内部总线传输的原生语义,英伟达NVLink便是基于内存语义,对标NVLink的UAlink等也是基于这种语义;消息语义则是采用类似Scale Out的DMA语义Send/Read/Write,将数据进行打包传输,亚马逊和Tenstorrent等公司便是基于消息语义打造Scale Up互联方案。
内存语义和消息语义各有千秋。内存语义是GPU内部传输的原生语义,处理器负担更小,在数据包体量小时效率更高;消息语义采用数据打包的方式,随着数据包体量变大,性能逐渐追上了内存语义,随着AI大模型体量增大,这一点也非常重要。
不过,田陌晨指出:“无论是内存语义还是消息语义,对于厂商而言,都面临一些共性的挑战,比如传统GPU直出将IO集成在GPU内部,性能提升受到了光罩尺寸的严格限制,留给IO的空间非常有限,IO密度提升困难;Scale Up网络和数据传输协议复杂,计算芯片厂商大都缺乏相关经验,尤其是开发交换机芯片的经验;除NVLink之外,其他Scale Up协议并不成熟且不统一,协议迭代对计算芯片迭代造成了巨大的困扰。”
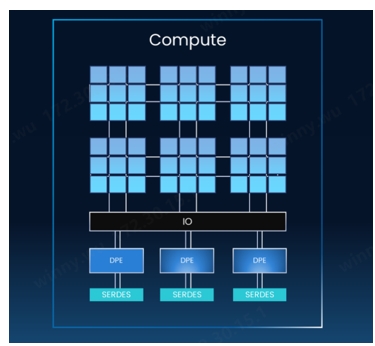
借助NDSA-G2G可以实现计算芯粒和IO芯粒解耦,通过通用芯粒互联技术UCIe进行互联。这样做的好处是,只需要牺牲一点点的芯片面积(小百分之几),就可以将宝贵的中介层资源近乎100%用于计算,并按照客户的需求灵活地增加IO芯粒的数量,且计算芯粒和IO芯粒可以基于不同的工艺技术。再加上IO芯粒的复用特性,能够显著提升高性能计算芯片的性能和性价比。
NDSA-G2G的第二大优势是提升IO密度和性能,具有高带宽、低延时和高并发的特性。在高带宽方面,基于NDSA-G2G芯粒,可以实现1TB级别的网络层吞吐量,TB级的GPU侧吞吐量;在低延时方面,NDSA-G2G芯粒提供百ns级的数据传输延时和ns级D2D数据传输延时;在高并发方面,该产品支持多达数百万个队列对,可扩展系统中的内存资源。也就是说,借助奇异摩尔NDSA-G2G芯粒能够赋能国产AI芯片实现自主突围,构建性能媲美英伟达NVSwitch+NVLink的Scale Up方案。

同时,田陌晨也呼吁:“希望科技行业在Scale Up方向上能够拥抱一种开放而统一的物理接口,实现更好的协同发展,这也是打造国产自主可控算力底座的关键一步。”
Scale Inside——全面提升计算芯片传输效率
在Scale Out和Scale Up 高速发展的过程中,作为算力基础单元,Scale Inside的进度也没有落下,并致力于通过先进封装技术弥补摩尔定律速度放缓的影响。在整个智算系统里,更高算力的计算芯片能够进一步提升Scale Up和Scale Out的性能水平,使得AI大模型的训练更加高效。
当前,单颗高性能计算芯片的成本已经非常恐怖,随着制程工艺进一步精进,这一数字还将继续飙升,因而Chiplet技术得到了广泛的重视。Chiplet技术允许通过混合封装的方式打造高性能计算芯片,也就是说计算单元和IO、存储等其他功能单元可以选择不同的工艺实现,具有极高的灵活性,允许厂商根据自己的需求进行定制芯粒,不仅能够显著降低芯片设计和制造的成本,良率也能够得到很大的改善。
在Scale Inside方向上,奇异摩尔能够提供丰富的Chiplet技术方案,包括Kiwi Link UCIe Die2Die接口IP、Central IO Die,3D Base Die系列等。其中,Kiwi Link全系列支持UCIe标准,具有业界领先的高带宽、低功耗、低延时特性,并支持多种封装类型。Kiwi Link支持高达16~32 GT/s的传输速率和低至ns级的传输延迟,支持Multi-Protocol多协议,包括PCIe、CXL和Streaming。
这些方案很好地践行了奇异摩尔公司的使命——以互联为中心,依托Chiplet和RDMA技术,构筑AI高性能计算的基石。“对于国产AI大模型和国产AI芯片产业而言,奇异摩尔的方案是新质生产力的代表,有着更大的潜能值得去挖掘。为实现国产AI芯片产业的‘中国梦’,奇异摩尔不仅提供支持最前沿协议的IO芯粒,以实现高速率、高带宽、低时延的传输表现,还在Chiplet路线上独辟蹊径,用创新的芯片架构助力打造更高性能的AI芯片。奇异摩尔愿与国内公司携手,为国产AI芯片产业发展添砖加瓦,共同勾画国产AI发展的广阔蓝图。”田陌晨最后说。
免责声明: 本文章转自其它平台,并不代表本站观点及立场。若有侵权或异议,请联系我们删除。谢谢! Disclaimer: This article is reproduced from other platforms and does not represent the views or positions of this website. If there is any infringement or objection, please contact us to delete it. thank you! |

关注矽源特公众号

矽源特微信客服
 发送邮件
发送邮件 商务QQ客服
商务QQ客服 13823761625
13823761625
